原创 Synced 机器之心
机器之心报道
参与:思、一鸣
深度学习对算力要求太高,怎么简化计算复杂度呢?北大、华为诺亚方舟实验室等提出完全用加法代替乘法,用 L1 距离代替卷积运算,从而显著减少计算力消耗。

近日,北大、华为诺亚方舟实验室等的研究者提出了一个名为 AdderNets 的网络,用于将深度神经网络中,特别是卷积神经网络中的乘法,转换为更简单的加法运算,以便减少计算成本。
在 AdderNets 中,研究者采用了 L1 正则距离,用于计算滤波器和输入特征之间的距离,并作为输出的反馈。为了取得更好的性能,研究者构建了一种特殊的反向传播方法,并发现这种几乎完全采用加法的神经网络能够有效收敛,速度与精度都非常优秀。
从结果来看,AdderNets 在 ResNet-50 上 对 ImageNet 数据集进行训练后,能够取得 74.9% 的 top-1 精确度和 91.7% 的 top-5 精确度,而且在卷积层上不使用任何乘法操作。
这一研究引起了深度学习社区的热议。
一些网友认为这是一个不错的研究,如果通过简化计算复杂度,让 CPU 运行本应当由 GPU 运行的计算,则是一个很好的改进了。



为什么需要替代乘法
有了 GPU 进行加速,即使是有着上亿浮点数乘法计算的卷积神经网络也可以得到加速。然而,高端 GPU 显卡具有很高的能耗,使得在移动设备上部署深度学习系统变得很困难。
加法、减法、乘法和除法是四种基本的数学运算。我们都知道,乘法比加法运行速度更慢,但是在前向计算中,深度神经网络中的大部分计算都来自浮点值权重和浮点激活值的乘法操作,因此许多研究都在探索如何将乘法换成加法。
其中一项开创性的工作便是 BinaryConnect。这一算法强制网络权重为二值化(如 -1 或 1),因此许多乘积运算被替换为简单的加法计算。
尽管通过二值化过滤器的深度神经挽留过极大地减少了计算量,但是网络也通常不太可能维持原来的识别精确度。此外,训练二值网络的过程也不是稳定的,经常会需要更慢的收敛速度和很小的学习率。
但实际上,经典 CNN 中的卷积计算实际上是对两个输入(输入特征和滤波器)之间进行互相关性的计算。这一点认知非常重要,这也是整篇论文的出发点。
既然卷积操作的实质是输入特征和给定滤波器之间进行的相似度度量计算,那么是否可以使用加法的方式代替乘法进行相似度计算呢?本文的研究者遵循这一思路想到了一种方法。
没有乘法的神经网络
在这篇论文中,研究者提出了一种名为 AdderNet 的神经网络,他们希望尽可能使用加法,而不像卷积运算那样大量使用乘法。想象一下,如果给定一系列微小的模式,并将它们作为神经网络中的「滤波器」,那么 L1 距离能很好地度量输入数据与模式之间的绝对差异。

如上图 1 所示,对于卷积网络来说,不同的类别可以通过角度来确定。而对于 AdderNet,因为采用 L1 距离度量不同类别的绝对误差,它的特征会像聚类那样聚集在不同的集群中心。研究者表示,这样的可视化旨在说明 L1 距离可以像卷积网络中的「滤波器」一样,它们都可以作为一种度量输入特征与特定模式之间距离的方法。
因为减法可以通过加法的补码(补码:用二进制进行正负变号的方法)来实现,因此 L1 距离同样对硬件非常友好,相当于它只会用了加法。这样只包含加法的运算,是替代卷积运算的一种好方法。当然,采用了 L1 距离,反向传播也需要修正,研究者设计了一种带正则梯度的方法以确保不同的「模式」能够有充足的更新,并构建更好的网络收敛行为。
研究者表示,他们设计的 AdderNet 已经在多种基准上做了充足的实验,令人惊喜的是,AdderNet 不仅能收敛到与传统 CNN 相近的准确率,同时推断速度还快得多。
从乘法到加法的卷积计算
原始的卷积计算如下所示,假设有一组滤波器
,它会对输入
执行卷积运算。其中 c_in、c_out 为输入和输出的通道数,H、W 分别为特征的高和宽。输出特征 Y 便是滤波器和输入特征的相似度度量,如下所示:

论文中,研究者将互相关性换成了 L1 距离,L1 距离是一种加法操作——用于计算两个向量表示之间所有点的绝对距离之和。

这样一来,卷积计算中最消耗算力的部分被代替,因此极大地加快了运算速度。
反向传播如何设计
原始的反向传播公式如下所示,其中 i ∈ [m,m+d],j ∈ [n,n+d]。要更新「滤波器」F,就要计算距离 Y 对 F 的偏导数,因为相似性是靠乘法 X*F 来计算的,因此偏导就为 X。
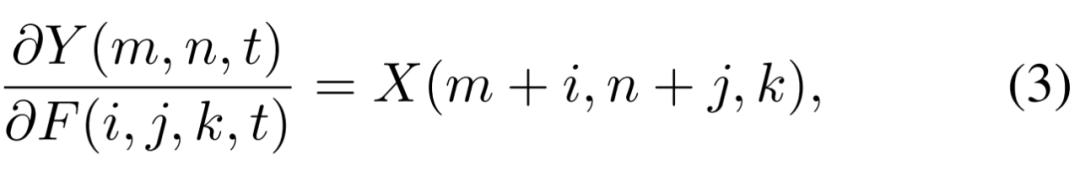

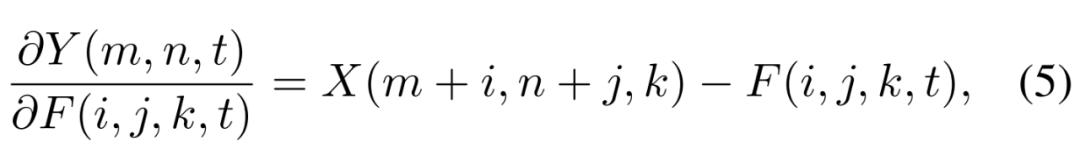
研究者将这种方法被称为全精度梯度(full-precision gradient),但是在没有符号函数整流的情况下,梯度可能会随着层积累而导致梯度爆炸的情况。因此,研究者加上了一个梯度裁剪操作,使对 X 的梯度限定在 [-1,1] 的范围内。最终的公式如下所示,其中 HT 是裁剪梯度的一个运算。

没有乘法的模型真的能收敛?
为了证明 AdderNet 的有效性,研究者在 MNIST、CIFAR 和 ImageNet 上测试了模型效果,同时也做了一系列对照实验来确定 L1 距离等不同模块的重要性。所有实验都是在英伟达 Tesla V100 GPU 和 PyTorch 上完成的。
首先对于 MNIST,研究者的方案是采用本文提出的 adder 滤波器替代 LeNet-5-BN 的卷积核,同时因为全连接层可视为特殊的卷积层,因此研究者采用减法代替了全连接层中的乘法。对于常规的卷积网络来说,最终约有 435K 乘法运算、435K 加法运算,而 AdderNet 只有 870K 加法,基本没有乘法。
在 MNIST 上,卷积与 Adder 都能获得 99.4% 的准确率。但从 CPU 的角度来说,加法的延迟要远远低于乘法,采用 Adder 运算的 LeNet-5 在 CPU 上能有∼1.7M 的延迟,而原版 LeNet-5 有∼2.6M 的延迟。研究者并没有继续对比 GPU 上的延迟,毕竟卷积经过了 CUDA 与 CuDNN 的高度优化,而 Adder 运算并没有。
随后研究者进一步在 CIFAR 和 ImageNet 上对比了不同方法的效果。这一次还是像 MNIST 那样用 Adder 运算替代卷积运算,只不过新加了二值神经网络(BNN),因为它可以通过 XNOR 运算代替乘法运算,整个实验保证其它条件都一致。

我们可以看到共有 1.3G 的总运算,CNN 会将其分配给乘法与加法,BNN 会分配给加法与 XNOR 运算,而 AddNN 完全采用加法。值得注意的是,在 CIFAR 数据集上,完全加法的神经网络在性能上也能媲美常规卷积神经网络。

与 CIFAR 数据集一一致,Adder 运算效果能媲美卷积运算,同时完全采用加法。最后,研究者还做了一系列对照试验,主要探讨到底什么样的梯度信号才能保证收敛的速度与准确性。如下图 3 所示,研究者提出的适应性学习率缩放与全精度梯度方法最终能达到最好的效果。

看了实验效果,先不管它的实际应用怎么样,就这样完全采用加法运算,还能收敛得如此优秀,足以说明用加法替代乘法是可行的、采用 L1 距离替代卷积运算也是可行的。之前机器之心挺少看到类似的研究,这样的方向说不定非常值得更多研究者去探索。
机器之心 AAAI 2020 论文分享进行到了第三期,本期我们邀请到了加州大学伯克利分校 Zhewei Yao 博士,他的论文《Q-BERT: Hessian Based Ultra Low Precision Quantization of BERT》被 AAAI 2020 所接收。在这期分享中,他将介绍把二阶方法用于训练深度神经网络的最新结果。
原标题:《深度学习可以不要乘法,北大、华为诺亚新论文:加法替代,效果不变,延迟大降》
